Hello and welcome back in this blog we will see how do we build a LLM based LangChain app from scratch.
Let us first try to understand an analogy before diving into the details.
Imagine you are trying to analyze a research paper and you get many doubts in that paper what you generally do go to ChatGPT and upload the PDF or Document and then start asking ChatGPT about the paper but if your using a free version you are limited with the number of chats per day.
So instead of giving your PDF to ChatGPT we can instead think of another approach…
What is another approach?
You can build an LLM based LangChain app which takes in the input as PDF and then answers to your queries.
This is quite confusing right.. Let us try to understand it step by step.
What is LangChain?
LangChain is an open-source Python framework that helps us to build AI powered apps using LLM‘s – like OpenAI GPT, Google Gemini, Meta’s LLM’s and etc.
Why LangChain?
Instead of writing manual code for to split documents, generate embeddings, retrieve them and give to LLM with LangChain it provides us with ready made modules (e.g, TextSplitter, DocumentLoader, Embeddings, VectorStores) that are put all together as ready made lego blocks with which we can play our own game.
That lets you quickly create Q&A apps, ChatBots, agents, and more — even on your own PDFs.

Now let us try to understand what is the process involved to build this LangChain app?
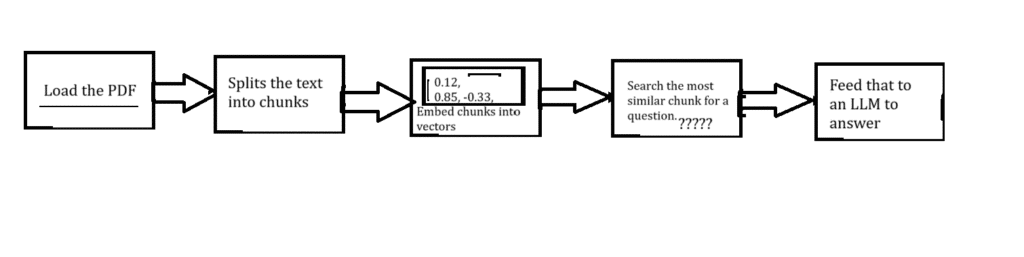
Now let us try to understand this flowchart step by step.
You try to first load the PDF and then this PDF text is split into chunks (RecursiveCharacterTextSplitter), which in turn is split into vectors (sentence-transformers/all-MiniLM-L6-v2), then store those vectors in a vector database for similarity search, then you search for the similar chunk for a question, and this question is fed to LLM for answer.
Now that you got a clear picture of what is happening at the background now let us get clear picture seeing the code of this.
Let us get started with the coding now:
Before getting into the coding part let us understand what are the requirements for this: 1. You need VSCode with the latest Python version -- 3.10 and pip version -- 25.1.1 python-dotenv -- to load env file and API keys langchain -- Core LangChain framework (text_splitter, RetrievalQA langchain-community -- Community contributions like PyPDFLoader, Chroma vectorstore langchain-google-genai -- Integration with Google Generative AI langchain-huggingface -- HuggingFace embedding model support sentence-transformers -- Provides the embedding model (all-MiniLM-L6-v2) chromadb -- the vector database pypdf -- PDF reader dependency 2. And all the pip libraries I'm mentioning below: pip install python-dotenv pip install langchain==0.2.1 pip install langchain-community pip install langchain-google-genai pip install langchain-huggingface pip install sentence-transformers pip install chromadb pip install pypdf 3. .env will store the API key of your desired LLM for this tutorial i'm using google gemini api. for getting your api refer to this tutorial API Key
import os
from dotenv import load_env
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.chains import RetrievalQA
load_dotenv()
#load the pdf
loader=PyPDFLoader("your_pdf.pdf")
docs = loader.load()
#Split the text into chunks
text_spitter = RecursiveCharacterTextSpitter(
chunk_size=1000, chunk_overlaps=200
)
chunks= text_splitter.split_documents(docs)
#Embeddings
embeddings = HuggingFaceEmbeddings(
model_name = "sentence-transformers/all-MiniLM-L6-v2"
)
#Vector store
vectorstore = Chroma.from_documents(chunks, embeddings)
# LLM — use a supported model
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
# QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 4}) # Give me the top 4 most similar chunks as context.
)
#Ask question — use invoke() instead of run()
question = "what does mab say and what is the ucb policy?"
answer = qa_chain.invoke({"query": question})
print(answer["result"])
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.chains import RetrievalQA
# Load environment vars
load_dotenv()
# Load the PDF
loader = PyPDFLoader("sample2.pdf") #sample pdf
docs = loader.load()
# Split into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
)
chunks = text_splitter.split_documents(docs)
# Embeddings
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# Vector store
vectorstore = Chroma.from_documents(chunks, embeddings)
# LLM — use a supported model
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash")
# QA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 4})
)
# Ask question — use invoke() instead of run()
question = "what does mab say and what is the ucb policy?" #sample query
answer = qa_chain.invoke({"query": question})
print(answer["result"])
So this is it for this tutorial if you like the content do share it with your friends and stay tuned for more such interesting content.